
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 컨설팅
- LLaMa
- 생성형
- GPT
- k8s
- POD
- 도커
- 쿠버네티스
- 메세지큐
- 컨설턴트
- kubernetes
- OpenShift
- fast api
- vuejs
- 오픈시프트
- 생성형 AI
- Machine Learning
- SpringBoot
- 솔루션조사
- vue.js
- 리트코드
- 로깅
- BFS
- Redis
- LeetCode
- fastapi
- jpa
- Docker
- 머신러닝
- Python
- Today
- Total
수 많은 우문은 현답을 만든다
Spring Batch 적용하기 본문
안녕하세요,
오늘은 Springboot Application에 Spring Batch를 적용하면서 고민했던 내용을 공유하려고 합니다.
현재 DDD(Domain Driven Design) 방식을 채택하여 개발을 진행하고 있으며 Bounded Context(도메인 경계)를 5가지로 구분했습니다. organization, settings, attendance, approval, batch 5가지 개별 모듈로 서비스가 구성되어있으며 각각의 필요에 의해 서로 의존성을 가지도록 설정했습니다. 오늘은 batch 모듈을 구성한 방식에 대해 간략히 설명하고 배치서비스 구성을 어떻게 구현했는지 설명하도록 하겠습니다.
1. Batch 모듈의 의존성 설정
우선 프로젝트의 build.gradle > dependencies에 모듈간 의존 관계를 설정해줍니다.

BatchApplication 에서는 접근이 필요한 다른 모듈들의 클래스들을 Bean으로 등록할 수 있도록 지정해줍니다.
이때, 모든 클래스들을 노출하지 않고 Controller는 외부 API로 사용할 계획이기 때문에 대상에서 제외했고 Service, Repository, Dto 등을 등록했습니다.
여기서 주의할 점은 무분별하게 컴포넌트들을 로딩하면 빈 이름이 중복될 수 있고, 필요없는 컴포넌트가 로딩되었을때 추가 의존관계를 필요로한다면 불필요한 작업이 증가됩니다. 이를 방지하기 위한 예시로, config 클래스 중 노출할 대상들만 config.shareable에 관리합니다.
부가적으로 Entity와 Repositories 의존관계를 설정하는 방법은 아래와 같습니다.
이제 Batch 모듈에서 다른 모듈들에도 접근할 수 있도록 설정이 끝났으니 Spring Batch를 적용해보도록 하겠습니다.
2. Spring Batch 적용
프로젝트는 아래와같이 구성했습니다.
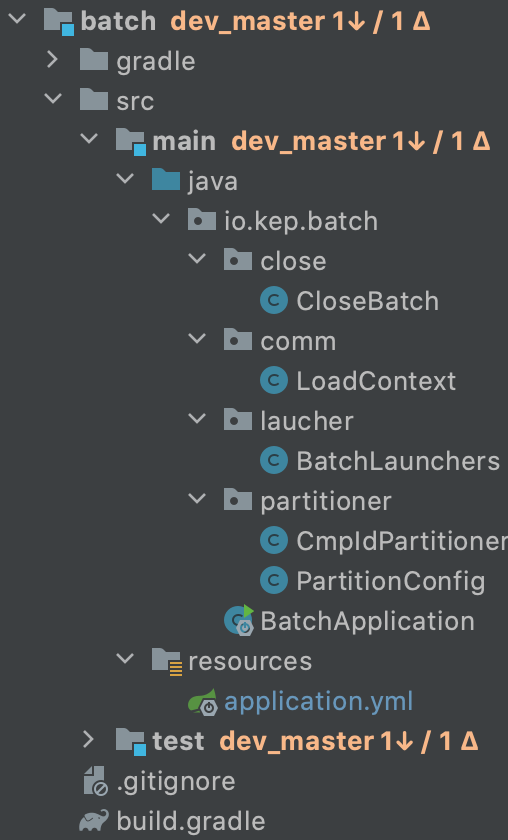
- closeBatch : 일정마감 관련 배치의 구성을 설정합니다. Job, Step, Tasklet 설정을 합니다.
ㄴ Job : 배치처리 과정을 하나의 단위로 만들어 놓은 객체.
ㄴ Step : Job의 배치처리 과정들을 순차적인 Step들로 정의합니다.
ㄴ Tasklet : 각 Step에서 실제 수행되는 로직을 정의합니다.
- BatchLunchuers : 스케줄을 등록해 배치를 실행시킵니다.
- Partitioner : company_id 를 10개씩 파티셔닝하여 처리하도록 멀티쓰레딩 설정을 합니다.
2-1. batch > luncher > BatchLunchers.java
우선 BatchLuncher를 먼저 살펴보겠습니다.
기능별 배치마다 @Scheduled 어노테이션을 사용해서 Batch Triggering 을 구성했습니다.
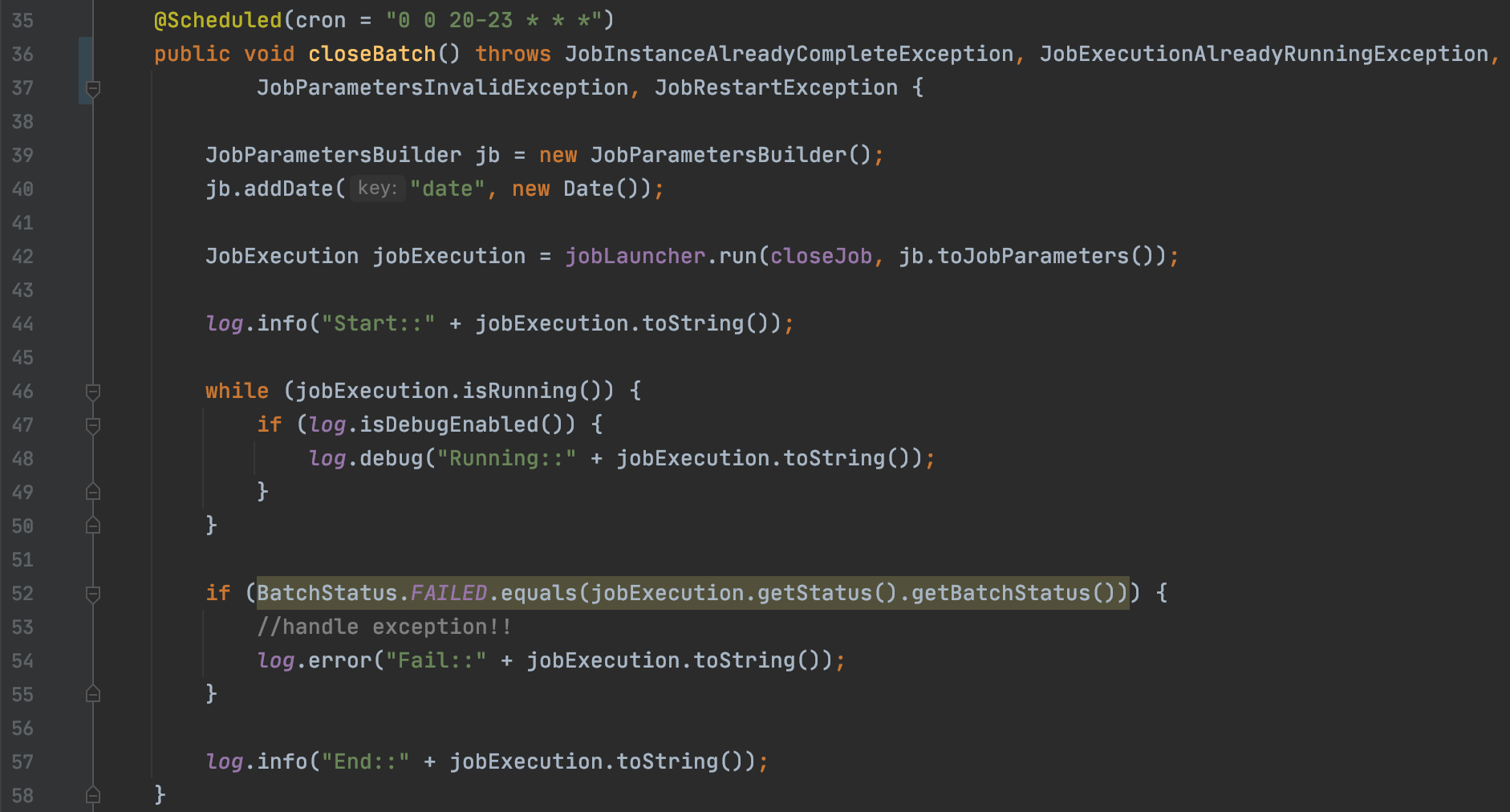
40 : 배치 작업이 수행될때 마다 전달되는 Parameter를 설정할 수 있다.
42 : Job과 파라미터를 jobLuncher에 등록해 Job을 실행시킵니다. 배치의 실행 단위를 JobExecution 이라고 합니다.
46 : 배치 프로세스가 도는 과정을 확인해볼 수 있습니다.
2-2. batch > partitioner > CmpIdPartitioner.java
이번엔 Partitioner를 살펴보겠습니다.
10만명 가까이 사용할 것을 대비해 고객 정보(company_id)를 기준으로 파티셔닝을 구성해 병렬처리를 하도록 설정합니다.
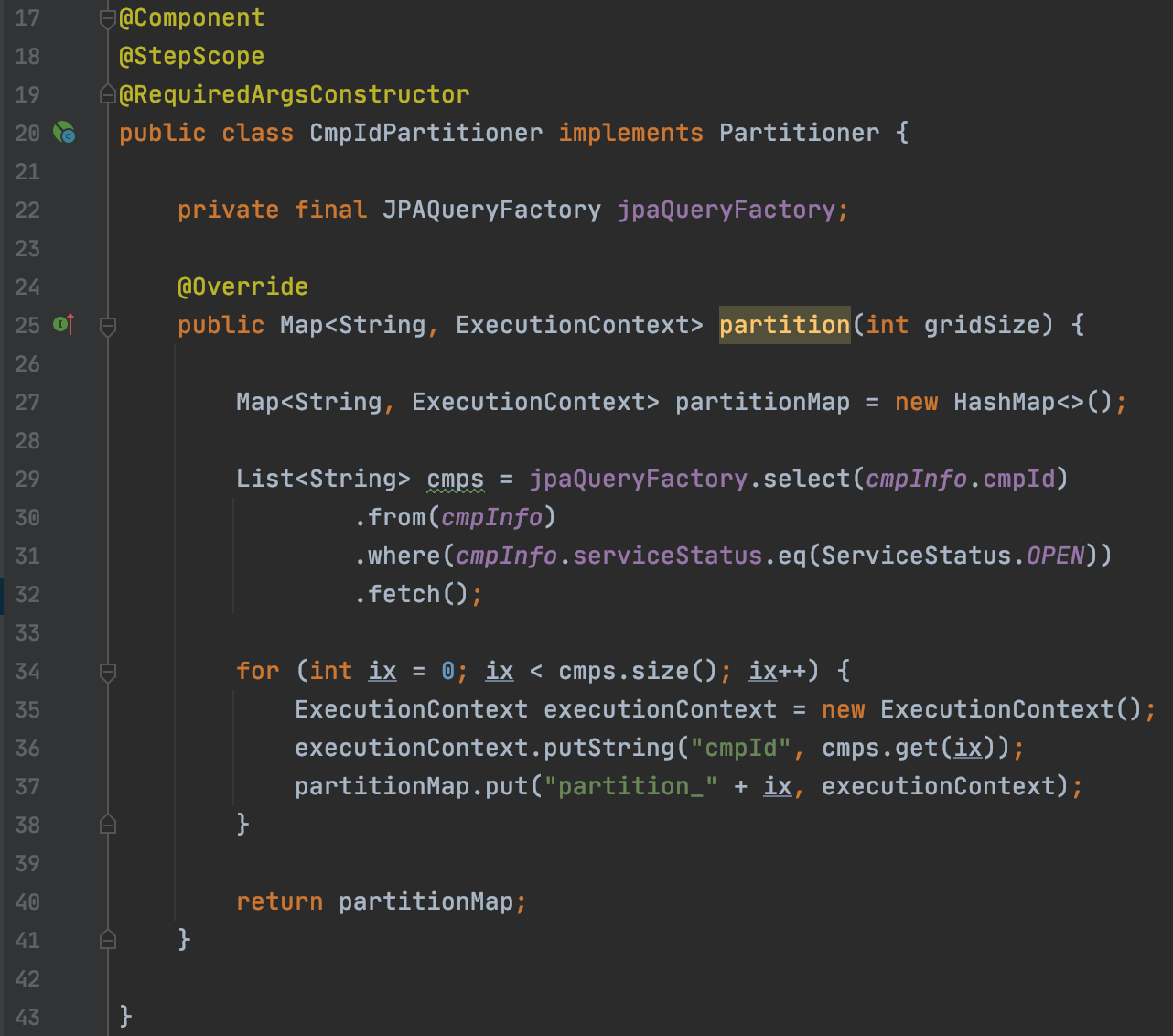
18 : @JobScope는 Step에, @StepScope는 Tasklet에 선언해 사용합니다.
스프링에서는 Bean으로 지정된 객체는 기본적으로 싱글톤 객체로 관리하지만, @JobScope, @StepScope 어노테이션을 사용하면
각 Step에서 별도의 Tasklet을 실행할 수 있어 병렬처리에 안전합니다.
이는 Late Binding 때문인데, @JobScope, @StepScope를 사용하면 Bean의 생성 시점을 애플리케이션 실행 시점이 아닌
지정된 Scope가 실행되는 시점으로 지연(Late Binding)시킵니다. Late Binding 의 장점은 로직이 실행되는 시점에 company_Id,
partition_id, date 등을 저장해 다음 Step 으로 전달하거나 처리 도중 에러가 난 경우 어디까지 데이터를 읽어 들였는지 확인해
실패했던 곳에서부터 재처리를 할 수 있다는 장점들이 있습니다.
34 : 사용자의 정보를 배치 데이터 저장소인 ExecutionContext에 저장합니다 (cmpId, partition1, 2, 3 ...)
2-3. batch > luncher > PartitionConfig.java
PartitionConfig에서는 병럴처리를 위한 멀티쓰레드 설정을 합니다.
실제 세팅을 공개하기 전에 기본적인 멀티쓰레드 동작 방식에 대해 살펴보겠습니다.
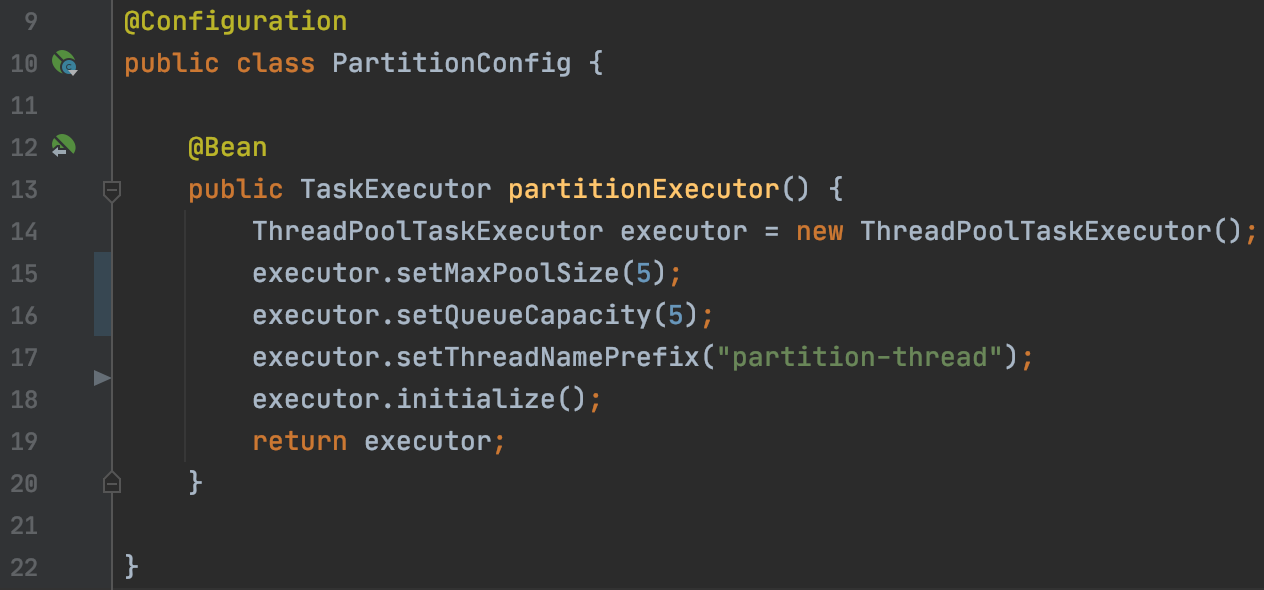
15 : 기본 풀 사이즈 설정 MaxPoolSize (default=1)을 은 생략하고, 풀의 최대 사이즈(QueueCapacity)는 5개로 지정합니다.
16 : 요청이 몰렸을때 요청들을 담아둘 큐 사이즈는 5개로 지정합니다.
<쓰레드 증가의 원리>
쓰레드 실행 execute 메소드에 corePoolSize 보다 많은 task가 들어오면
WorkQueue에 task들을 대기시키고 WorkQueue가 가득 찬 경우에만 새 쓰레드들이 생성됩니다.
위 설정대로 실행을 시켜보면 아래와 같은 결과를 얻을 수 있습니다.
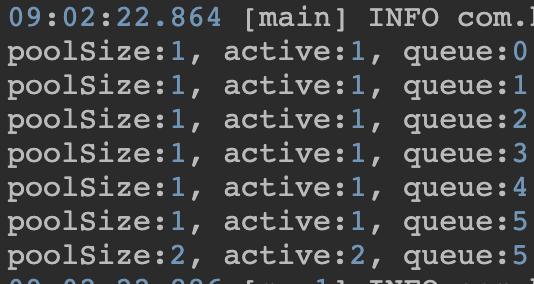
corePoolSize=1 : 처음에는 active thread 가 1개입니다.
QueueCapacity=5 : 6번째 task 까지는 active thread 가 1개로 유지됩니다. 대신 queue 사이즈가 증가합니다.
MaxPoolSize=5 : 7번째 task 부터는 active thread 가 2개로 증가합니다.
MaxPoolSize 를 초과하는 task 를 요청하면 아래와같이 TaskRejectedException이 발생하니 주의해야합니다.

최종적으로 설정한 결과는 아래와 같습니다.

CorePoolSize : 1 -> 10
MaxPoolSize : 5 -> 10
QueueCapacity : 5 -> 1024
<Core, Max, Queue 사이즈는 어느정도가 적당할까?>
8 core 서버를 기준으로 PoolSize, QueueCapacity 를 어느정도로 설정하면 '적당하다'고 할 수 있을지 고민을 해봤습니다.
- setCorePoolSize :
배치 작업은 자원을 최대한 사용해 빠르게 처리를 해야하기 때문에 8core 기준 120% 인 10개로 설정했습니다. - setMaxPoolSize :
사용자 요청이 많은 서비스였다면, 논리적 thread는 더 늘어날 수 있기 때문에 100개 정도로 설정해보고 connection 수에 따른 성능을 모니터링 했을 것 입니다. 하지만, 배치에서는 쓰레드 수가 늘어나도 시분할 처리를 하기 때문에 배치 종료까지의 총 시간은 동일합니다. 그래서 하나의 배치가 돌때 한 작업을 집중해서 끝낼 수 있도록 쓰레드 수를 고정시켰습니다(core = max = 10)
(참고로 긴 배치는 수 시간도 넘어갑니다 !!) - setQueueCapacity : 기본적으로 배치가 시간을 많이 필요로하기 때문에 동작 시간이 겹치지 않도록 스케쥴링을 했지만, 혹시 작업이 겹치는 일이 생기더라도 1000개 정도의 task는 대기할 수 있게 설정했습니다. 이를 초과하면 문제가 있다고 판단할 수 있습니다.
2-4. batch > close > CloseBatch.java
CloseBatch 에서는 일정 마감(close) 관련 Bean들인 Job, Step, Tasklet 을 생성합니다.

41 : GridSize(n) 는 몇 개의 StepExecution을 생성할지 결정하는 설정값이다.
여기서 n 값은 PartitionConfig에서 설정해주었던 corePoolSize(m) 의 m 값과 같아야 m개의 쓰레드가 n개의 스텝을 처리합니다.
Job과 Step을 생성하는 과정입니다.

Tasklet 설정 코드입니다.
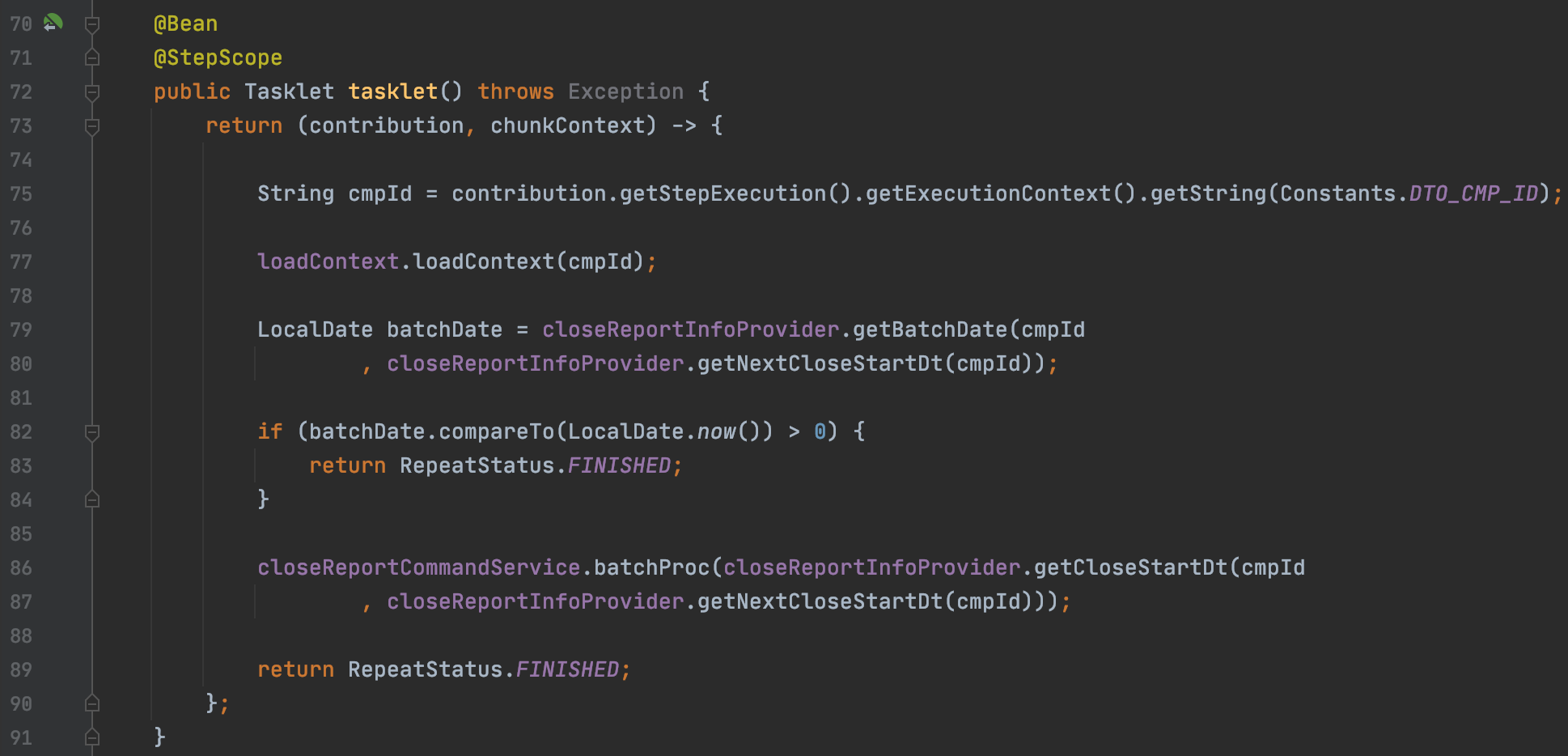
75 : tasklet이 실행되면 executionContext에 저장했던 cmpId를 넘겨받습니다.
cmpId를 각 모듈별 서비스에 파라미터로 넘겨서 비즈니스 로직이 수행되도록 합니다.
감사합니다.
'개발지식 > Springboot' 카테고리의 다른 글
| FK 를 쓰지 않는 이유 (0) | 2022.03.21 |
|---|---|
| 예외처리에 대한 고찰 - 3편 (성능 개선) (1) | 2022.03.09 |
| 예외처리에 대한 고찰 - 2편 (로깅 기능 설계) (0) | 2022.02.24 |
| 예외처리에 대한 고찰 - 1편 (0) | 2022.02.21 |
| JPA 와 N+1 문제점 (0) | 2022.01.22 |



