선형 선형회귀란, 주어진 데이터 집합에 대해 종속변수와 n개의 독립변수 사이의 선형 관계를 모델링 하는 것을 말한다. 수식으로 예를들면 y=ax+b (y: 종속변수, x: 독립변수) 처럼 표현할 수 있고 독립변수는 input, 종속변수는 output의 개념으로 생각할 수 있다. 즉 선형회귀는 집합에서 최적의 선을 찾는게 목표이며 독립변수의 계수들이 선형관계에 있는것을 선형이라 한다. 선형회귀는 위 수식처럼 y=ax+b 처럼 표현할 수 있고 b는 절편(=bias), 그리고 a는 기울기 또는 가중치(wieght)라고 한다. x는 파라미터 값으로 직접적인 컨트롤을 할 수 없으며 우리가 궁극적으로 구하려는건 a와 b의 값을 구해서 y(=price, 확률 등)을 구하는것이다. 참고로 기울기는 미분 수식으로 구할 수 있다.
비선형 반대로 비선형은 독립변수의 계수들이 선형관계가 아닌것으로, 로지스틱 회귀의 시그모이드 함수를 보면 독립변수가 또다른 독립변수가 된다던가 하는 일이 발생한다. 비선형으로는 신경망 이론이 있으며 신경망 이론은 선형모델과 비선형 모델의 결합으로 이루어져있다(선형수식 * 비선형함수 = 비선형수식)
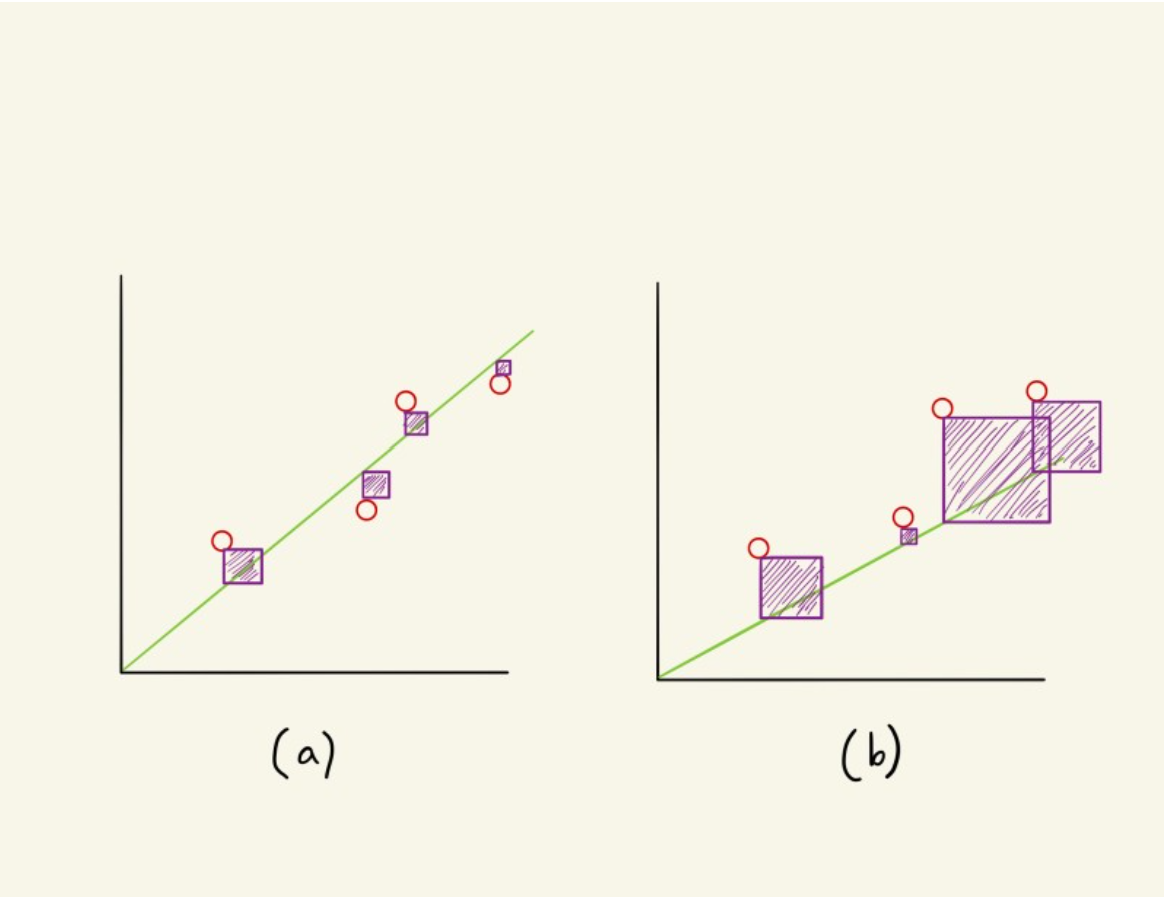
선형 회귀 왼쪽이 더 좋은 모델
왼쪽의 오차 분포가 더 적기때문에 왼쪽을 더 좋은 선형회귀 모델이라고 할 수 있겠다.
제곱손실 예측된 값과 실제 값 사이의 차이를 제곱한뒤 차이를 구해 오차를 측정한다. 작은 오차에 대해 작은 손실을 부여하며, 큰 오차에 대해 큰 손실을 부여하는 특성을 갖고 학습 과정에서 손실을 최소화하는 방향으로 모델을 업데이트합니다. 보라색 영역이 제곱손
MSE(mean squared error) 보라색 영역을 뜻하고 오차 점의 제곱의 차를 구한 오차 영역을 구한것이다.
LMS(least mean square) 좋은 선형모델을 찾기 위해서는 MSE가 작아야하고 이 과정을 LMS라 한다.
벡터화(Vectorization) 코드를 벡터화하면 속도가 10배 이상 향상되는 경우가 많습니다. 또한, 우리는 수학적 계산을 라이브러리에 맡기므로 직접 계산하는 양을 줄여 오류 가능성을 줄이고 코드의 이식성을 높일 수 있습니다.
손실 함수(loss function) 머신러닝 혹은 딥러닝 모델의 출력값과 사용자가 원하는 출력값의 오차
엔트로피(Entropy) 정보이론에서의엔트로피는 불확실성을 나타내며엔트로피가 높다는 것은 정보가 많고 확률링 낮다는 것을 의미
Training 객체지향 설계 학습 API를 설계시 필요한 클래스들을 정의할때 객체화하면 프로젝트를 단순화 할 수 있다. 보통은 모듈(모델, 손실 함수 및 최적화 방법), 데이터 모듈(훈련 및 검증을 위한 데이터 로더), Trainer 클래스 세가지로 분리해 구성하며 병렬 훈련 및 최적화 알고리즘에 대해 논의할 때 Trainer 클래스에 대해서만 논하면 된다.
Training 절차 학습이 진행되는 절차는 아래와 같다.
매개변수를 정한다 (가중치)
선택된 매개변수로 손실값을 구한다
손실 함수의 기울기(Gradient)를 계산한다
계산된 기울기와 학습률을 이용해 다음 가중치 위치로 이동한다 (이동은 경사하강법 사용)
파라미터를 업데이트 한다.
이동한 지점에서 손실함수의 기울기를 계산하고 위 과정을 반복한다.
손실함수의 기울기가 최소값에 도달하면 파라미터 업데이트를 멈춘다.
Training 단위 데이터가 많아질 수록 당연히 학습에 걸리는 시간은 길어진다. 그에대한 전략으로 epoch, batch size, iteration 이라는 개념이 등장했다.
epoch 모델이 전체 학습데이터를 1회 학습하면 1 epoch라고 한다. epoch가 높아지면 여러 가중치로 학습하므로 적합한 파라미터를 찾을 수 있으나 과적합이 발생할 수 있다. * 과적합 : 과적합은 너무 학습데이터를 완벽하게 학습한 것을 의미하며 학습하지 않은 데이터가 들어오면 원하는대로 동작하지 않을 수 있다. weight decay 는 일정 패널티를 줘서 데이터를 너무 완벽히 학습해서 오버피팅이 일어나지 않게 하는 하이퍼파라미터 장치이다.
batch size 한번의 배치에 해당하는 데이터 셋을 mini batch라 하며, 1회 epoch 안에 n개의 mini batch가 포함된다.
Iteration 1 epoch를 마치는데 필요한 파라미터 업데이트 횟수로 배치마다 파라미터 업데이트가 발생한다 (배치 수 = 파라미터 업데이트 수)
파라미터와 하이퍼파라미터
파라미터 모델 파라미터라고도 하며, 모델에 적용해 새로운 샘플에 대한 예측을 하기 위해 사용